Dataset statistics for Amazon dataset
This dataset if created from the raw data, available at UCSD repository.
To fine-tune the recommendation model we use a slice of the original dataset, with a text-rich users in mind, which might, however, have few reviewed books.
First, we filter the users to have at least 3 reviews (for training, test and validation splits). Note, that unlike pervious studies we don't remove the long tail of users with few interactions.
Further, we sort the users based on the average length of a review per book, and take 1k users with the largest review lengths.
For delivering the recommendations to the end users of the demonstration, we increase the overall pool of items, to ensure comprehensiveness of the results.
We top up the pool of items to be 100k, which results in 85% of the items being unseen by the model during training, which, however, does not hinder much the results of recommendation.
To get the desired 100k pool size, we first sample 50k top books by popularity. The remaining 35k are sampled by taking most popular books from each of top 1000 genres, to diversify the item collection.
In the demonstration, we mark for each item, how many reviews were written for it; 0 reviews means that the item was unseen.
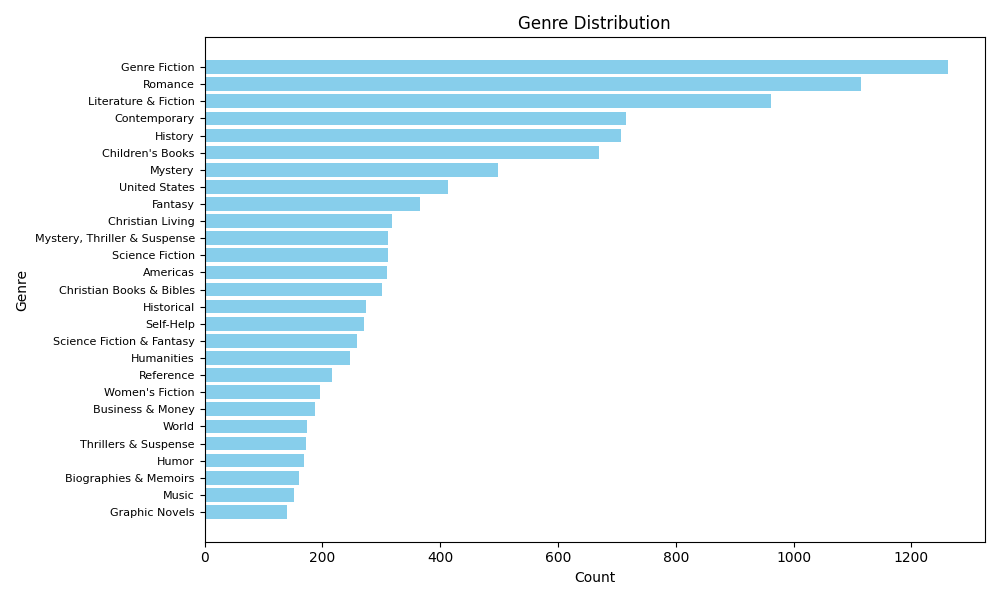
We analyze the distribution of top-50 genres in the resulting item pool, to get an idea about the topical biases in the dataset.
From the following chart we can observe that fiction literature is the dominant genre. Surprisingly, children's book is also very popular.